RLVR for Code Agents:当强化学习学会「自己批改作业」
从 RLHF 到 RLVR:一个范式转变
2025 年 AI 训练领域最大的叙事转折,不是新架构,不是更大的数据集,而是反馈信号的来源变了。
我们不再问人类「哪个回答更好?」(RLHF),而是让程序判断「这个回答对吗?」(RLVR)。
这个转变对代码 Agent 的影响尤其深远——因为代码是天然可验证的。单元测试通过/不通过,编译成功/失败,性能提升/下降——这些都是客观的、可程序化判定的信号。RLVR 将这种天然可验证性转化为系统性的训练范式。
本文将深度剖析 RLVR 在代码 Agent 领域的技术机制、关键突破、深层争议和未解难题。
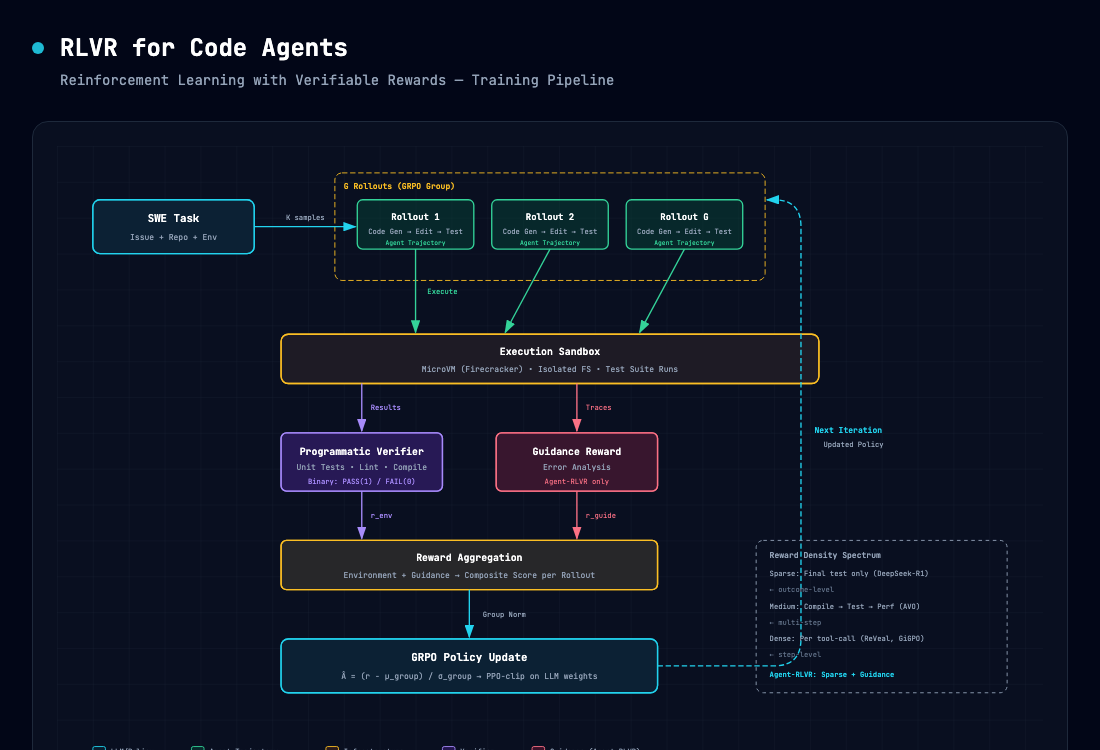
RLVR 的本质
RLVR(Reinforcement Learning with Verifiable Rewards) = 用程序化验证器(而非人类偏好模型)驱动的强化学习训练范式。
与传统 RLHF 的核心区别:
- RLHF:人类标注偏好 → 训练奖励模型 → PPO 优化策略。反馈是主观排序。
- RLVR:程序验证器(单元测试、编译器、执行结果)→ 直接计算奖励 → GRPO 优化策略。反馈是客观真值。
代码领域的验证器极其丰富:编译检查、单元测试、集成测试、性能基准、静态分析、lint 规则——每一个都可以成为 RLVR 的奖励信号源。
GRPO:RLVR 的核心引擎
为什么 RLVR 不用 PPO?PPO 需要学习一个 value function(critic)来估计状态基线。在代码 Agent 的多轮工具调用场景中,状态空间指数级爆炸,critic 难以收敛。
GRPO(Group Relative Policy Optimization) 的解决方案是「组内比较」:
对同一 prompt 生成 G 个回答(一组)
计算组内归一化优势:
A_i = (r_i - mean(r₁…r_G)) / std(r₁…r_G)核心特性:
- Critic-free:无需学习 value function,内存占用大幅降低
- 相对奖励:不关心绝对分数,只关心「比组内平均好多少」——天然对不同难度做自适应归一化
- 鲁棒性:对奖励的仿射变换不敏感
但 GRPO 有一个致命盲区:当一组回答全部正确或全部错误时,方差为 0,优势为 0,梯度消失。这在代码 Agent 训练中频繁发生——SWE 任务往往「要么全对,要么全错」。NGRPO(Negative-enhanced GRPO)通过引入虚拟最大奖励样本和非对称裁剪部分解决了此问题。
奖励设计的五级谱系
代码 Agent 的 RLVR 中,奖励密度是最关键的设计选择:
稀疏 ←──────────────────────────────────────→ 密集
│ │
最终测试通过 编译通过 中间步骤正确 每轮工具调用正确
(DeepSeek-R1) (AVO) (GiGPO) (ReVeal)稀疏奖励(Outcome-only)
DeepSeek-R1 开创:仅奖励最终答案正确性。代码场景下即「整个 patch 的测试是否通过」。优势是简单无奖励工程,劣势是在长周期任务中信号极度稀疏——Agent 做了 20 步操作,只有最后一步有信号。
多步验证奖励
AVO(Agentic Variation Operators)的模式:编译 → 正确性 → 性能 → 回归 → 提交。每步失败即终止,成功则累积奖励。问题:一旦某步失败,后续步骤的反馈永远丢失——Agent 永远不知道「如果编译通过了,性能会不会有提升」。
密集奖励(Dense Per-Turn)
ReVeal 对每轮工具调用都给予奖励,利用自生成测试提供即时反馈。GiGPO(NeurIPS 2025)更进一步:双层优势——Episode 级宏观 + 步骤级锚点分组。在这些密集奖励范式下,Agent 可以在每一轮操作中学习。
Agent-RLVR:从竞技编程到真实软件工程的跨越
Scale AI 的 Agent-RLVR(arXiv: 2506.11425)是代码 Agent RLVR 的里程碑工作:
Qwen-2.5-72B-Instruct on SWE-bench Verified:
无 RLVR → 9.4% PASS@1
Agent-RLVR → 22.4% PASS@1(+138%)
核心创新在两阶段奖励:
- Environment Reward:Agent 尝试解决任务 → 在沙箱中执行 patch → 单元测试验证 → 通过=1,失败=0(传统 RLVR)
- Guidance Reward:利用错误信息、补丁对比、成功轨迹等多种信号,主动引导 Agent 走向正确解法。这突破了「纯 outcome reward 过于稀疏」的瓶颈
训练数据为 817 个精选 SWE 训练环境,每个包含问题陈述 + 完整执行环境 + guidance 信号。关键洞察:纯 outcome reward 在 SWE 任务上效果极差,必须注入 guidance——这是代码 Agent RLVR 与数学 RLVR 的本质区别。
RLVR 的「肮脏秘密」:能力 vs 采样效率之争
2025 年下半年,一系列研究动摇了 RLVR 的叙事基础:
Limit of RLVR(NeurIPS 2025)
Base 模型的高 k 采样已经包含所有正确答案。RLVR 提升的是 pass@1,不是 pass@k 上限。RLVR 模型本质上是「高效采样器」,而非「更聪明的模型」。
清华大学团队的系统性研究显示:在 base 模型上通过大量采样(pass@k, k 足够大),可以找到 RLVR 训练后模型能找到的每一个正确推理路径。RLVR 没有扩展推理能力的边界——它只是让好的推理路径在低 k 时更可能被选中。
随机奖励实验(UW, 2025)
对 Qwen 2.5 Math 使用完全随机的奖励函数训练 RLVR,MATH 分数仍提升 15-20 分。
这暗示 RLVR 的增益可能部分来自 RL 训练本身的正则化效应(强制模型更聚焦、更少发散),而非验证器的质量。如果随机奖励都能带来提升,那我们在优化什么?
对代码 Agent 的推论
这个争议在代码领域有微妙但关键的差异:
- 数学推理:答案空间相对有限,通过大量采样确实可能覆盖——RLVR 增益可能主要是「高效采样」
- 代码工程(SWE):patch 空间巨大(定位文件 → 理解上下文 → 编辑多行 → 处理依赖),单靠采样几乎不可能碰对——RLVR 的结构化探索 + guidance 信号确实扩展了有效能力边界
Agent-RLVR 的 9.4% → 22.4% 跳跃不太可能仅靠「高效采样」解释。
多轮 RL 的 Credit Assignment 难题
代码 Agent 是多轮顺序决策问题。典型 SWE 任务中,Agent 需要:理解 issue → 搜索代码库 → 定位文件 → 编辑 → 运行测试 → 发现失败 → 修复 → 再测试。核心挑战是 credit assignment:第 3 轮的错误导致第 15 轮的最终失败,如何让梯度信号精确指向第 3 轮?
| 方法 | 机制 | 效果 |
|---|---|---|
| GRPO(原始) | Episode 级奖励,无步骤分配 | 信号粗糙 |
| GiGPO | Episode 级宏观 + 步骤级锚点分组 | ALFWorld +12%, WebShop +9% |
| μCODE(ICML 2025) | 单步奖励 + Best-of-N 搜索 | 显著超越 SOTA |
| ReVeal | 每轮自验证 + 密集奖励 | Pass@k 显著提升 |
GiGPO 的锚点分组机制尤为精妙:回溯性地在不同轨迹中找到相同的环境状态(例如「都在第 5 步打开了同一个文件」),构建步骤级比较组——不需要预定义步骤奖励函数。这是目前多轮 Agent RL 中最优雅的 credit assignment 方案。
工业实践全景
| 组织 | 工作 | 核心贡献 |
|---|---|---|
| Scale AI | Agent-RLVR | 817 SWE 训练环境 + guidance reward |
| SWE-Gym | 训练 + 验证联合 | 19% 绝对增益 |
| NVIDIA | Nemotron 3 Super | 21 环境 × 37 数据集联合 RLVR 训练 |
| Fireworks | Multi-turn RL 最佳实践 | RL ≫ SFT for multi-turn agents |
| Tsinghua | SWE-Dev | 训练 + 推理双重扩展 |
| Nebius | 搜索增强 Agent | 40.6% on SWE-bench(纯开源栈) |
五个未解决的深层问题
1. 验证器即天花板
Agent 的能力上限 = 验证器能覆盖的正确性范围。SWE-bench Verified 到 Pro 的骤降(70%+ → 23%)暴露了验证器设计本身就是瓶颈。一个只能检查「patch 是否通过原始测试」的验证器,无法区分「巧妙绕过测试的假修复」和「真正解决问题的修复」。
2. Guidance 的隐式作弊风险
Agent-RLVR 的 guidance 信号如果包含「答案线索」(例如错误信息精确指出了需要修改的文件和行数),RLVR 学到的是利用 guidance 而非真正理解和解决问题。这类似于「考试时偷偷看到了参考答案」——分数高不等于能力强。
3. 同质奖励组的梯度消失
SWE 任务中频繁出现「全 0 组」(全部轨迹失败),GRPO 的梯度消失导致这些最难的问题反而完全没有学习信号。NGRPO 只部分解决——在极端稀疏的场景下仍会退化。
4. 环境工程 > 算法创新
当前瓶颈越来越从算法转向训练环境的质量和多样性。Agent-RLVR 投入环境构建的工程远大于算法改进。这暗示 RLVR 可能正在进入「数据瓶颈」阶段——类似预训练的 Scaling Law,RLVR 的性能上限由训练环境决定。
5. 验证器的验证器悖论
验证器越精确 → 奖励信号越可靠 → 训练效果越好。但验证器本身也是代码(测试用例),其质量依赖人工编写。这形成了新的依赖链:人工标注 → 测试用例质量 → 验证器精度 → RLVR 效果。自动化测试生成(如 SAGA、TCGBench)旨在打破这个链,但目前精度仍不足。
与 Harness Engineering 的连接
回到更宏观的视角:
RLVR = 自动化训练信号 「这个 patch 对吗?」
GEPA = 自动化提示优化 「怎么让 Agent 少犯这个错?」
Harness = 约束 + 验证 + 进化 「Agent 不能做什么」
三者的统一是代码 Agent 完全自主进化的终极形态。
当前缺口:RLVR 优化模型权重,GEPA 优化提示文本,二者操作的是不同的参数空间。下一代框架将实现耦合——RLVR 的训练信号直接驱动 GEPA 的反思式进化,形成「验证 → 反思 → 改进 → 再验证」的自主闭环。这是 Hermes Self-Evolution 的五阶段路线图中隐含但尚未实现的目标。
代码 Agent 的 RLVR 不仅仅是训练技巧——它是 Agent 基础设施从「手工调参」到「自主进化」的转折点。谁先解决好验证器质量和信用分配这两个核心问题,谁就能率先构建真正自我改进的代码 Agent 系统。
参考
- Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards — arXiv:2506.11425, Scale AI (2025)
- ReVeal: Self-Evolving Code Agents via Reliable Self-Verification — arXiv:2506.11442 (2025)
- Limit of RLVR — NeurIPS 2025, limit-of-rlvr.github.io
- GiGPO: Group-in-Group Policy Optimization for LLM Agent Training — NeurIPS 2025
- μCODE: Multi-Turn Code Generation Through Single-Step Rewards — ICML 2025
- "Reasoning LLMs Are Just Efficient Samplers" — Tsinghua University (2025)
- SWE-Gym: Training Software Engineering Agents and Verifiers — OpenReview (2025)
- Nemotron 3 Super: Multi-Environment RLVR — NVIDIA Docs (2025)
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning — arXiv:2501.12948
- Hermes Agent Self-Evolution — github.com/NousResearch/hermes-agent-self-evolution
技术声明
本文技术分析基于上述公开论文和工业报告。Agent-RLVR 和 ReVeal 的架构细节来自其 arXiv 论文;「Limit of RLVR」的结论基于 NeurIPS 2025 接收论文的系统性实验;随机奖励实验的发现来自 UW 团队的非正式报告。GRPO 算法分析基于 DeepSeek-R1 技术报告及相关复现研究。关于「RLVR 增益在 SWE 场景中更多来自能力扩展而非采样效率」的判断为基于当前数据的合理推断(⚠️),有待更多对照实验验证。