Graph of Skills 深度分析:基于 PPR 的图结构 Skill 检索——GraSP 的开源参考实现
两周前分析 GraSP 论文时,我们注意到一个关键问题:论文四阶段的 Stage 1(Memory-Conditioned Retrieval)是所有后续 DAG 编译和执行的基础,但 GraSP 本身没有公开代码。幸运的是,同一时期出现了另一个高度相关的开源项目——Graph of Skills (GoS),它恰好实现了 GraSP Stage 1 的核心能力:从大规模 skill 库中精准检索相关技能。
项目定位
GoS(arXiv: 2604.05333,142⭐,12 forks)由 Lehigh University / DL Penn 团队开发,核心冲突与 GraSP 互补:GoS 解决检索层(query → skill bundle),GraSP 解决执行层(skill → verified action)。两者在同一时期独立发表,切入点不同但可以级联使用。
| 维度 | GoS | GraSP |
|---|---|---|
| 切入层 | 检索层 | 执行层 |
| 图构建 | 离线 index 时一次性建图 | 每个 task 运行时实时编译 DAG |
| 核心算法 | PPR + 双路召回 + 多因子 Rerank | Typed DAG + 局部修复 O(d^h) |
| 输出 | 排序后的 skill 列表 + 关系 | 可执行 DAG + 验证状态 |
| 开源 | ✅ 完整 + MCP 插件 | ❌ 无公开代码 |
架构全景
GoS 的核心 pipeline 分两层:离线建图(index)和在线检索(retrieve),以下是用 ComfyUI / Flux.2 Klein 生成的架构全景图:
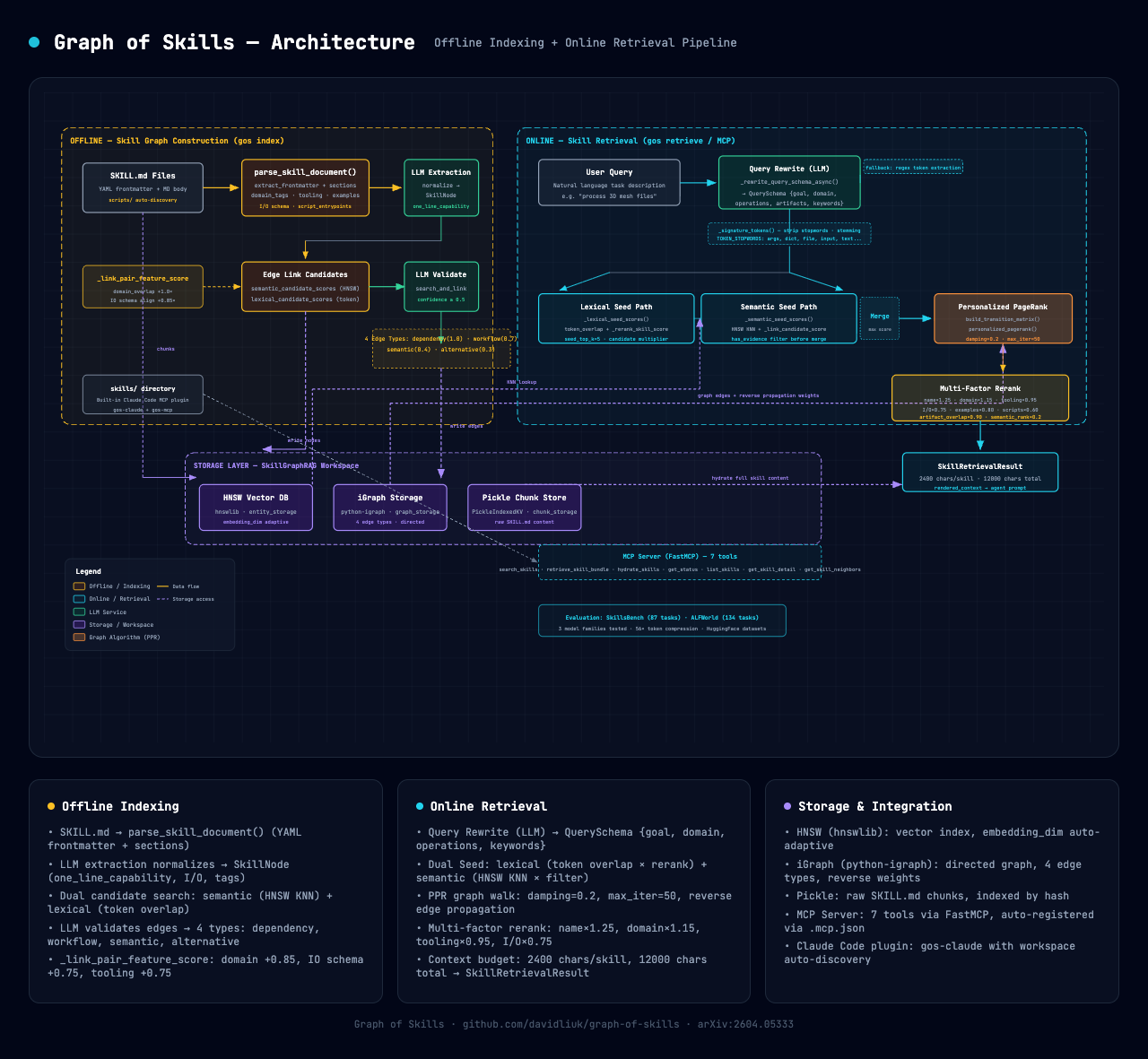
下面逐层拆解每个阶段的技术细节。
离线阶段:Skill 图构建
2.1 存储引擎
GoS 基于 fast_graphrag 框架,底层使用三种存储:
- HNSW (hnswlib) — 向量索引,存储 skill 的 embedding,用于语义 KNN 召回
- iGraph (python-igraph) — 有向图存储,节点 = skill,边 = 关系类型,用于 PPR 图游走
- Pickle — 序列化存储 chunk 数据
一个精妙的设计是嵌入维度自适应:如果预构建 workspace 的 HNSW 索引维度与当前配置不同(比如换了 embedding 模型),GoS 会自动 override 到 workspace 维度,避免维度不匹配的运行时错误。
2.2 四种边类型与权重体系
GoS 定义了 4 种边类型,每种在正向和反向传播中权重不同:
# 正向权重 (边链接时)
TYPE_WEIGHTS = {
"dependency": 1.0, # A 产出 → B 消费
"workflow": 0.7, # 常见链式工作流
"semantic": 0.4, # 同一能力簇
"alternative": 0.3, # 不同实现解决同一问题
}
# PPR 逆向传播权重
DEFAULT_REVERSE_WEIGHTS = {
"dependency": 1.0, # 依赖关系双向等权传播
"workflow": 0.5, # 工作流反向减半
"semantic": 0.2, # 语义反向极弱
"alternative": 0.1, # 替代关系几乎不反向传播
}边链接的核心逻辑是 "Prefer sparse, high-precision edges":只有共享 domain ≥50%、共享 tooling ≥50%、或 I/O schema 对齐时才建边。无证据时不建边,避免图噪音。
2.3 SKILL.md 解析器
GoS 的 parser 恰好理解 Hermes 的 SKILL.md 格式(YAML frontmatter + markdown body),从以下维度提取结构化字段:
- YAML frontmatter: name, description, inputs, outputs, domain, tags, tooling, examples, compatibility, allowed-tools
- Fallback 到 markdown sections: ## Inputs, ## Outputs, ## Examples 等
- 自动发现 scripts/ 目录的 .py/.sh/.js/.ts 文件作为
script_entrypoints - 从 body 提取第一句话作为
one_line_capability
在线阶段:四阶段检索 Pipeline
3.1 Stage 1 — Query Rewrite
用 LLM 将自然语言查询重写为结构化的 QuerySchema:
QuerySchema = {
goal: "任务意图描述",
task_name: "短 slug",
domain: ["技术领域"],
operations: ["API, 算法, 转换操作"],
artifacts: ["文件名, 格式, 接口"],
constraints: ["约束条件"],
keywords: ["高价值检索词"],
}Query Rewrite 失败时(LLM 不可用或超时),自动 fallback 到词法提取:正则匹配文件名(.py/.json/.csv 等)+ 签名 token 生成。
3.2 Stage 2 — 双路 Seed 召回
这是 GoS 的核心创新点。不同于传统的纯向量检索,GoS 采用双路并行召回:
Lexical Path(词法路径):
query_tokens = signature_tokens(query_schema) # 去停用词 + stemming
for node in nodes:
overlap = query_tokens & node_tokens
if overlap:
score = len(overlap) / len(query_tokens)
score += rerank_skill_score(node) # 多因子加权Semantic Path(语义路径):
query_embedding = embedding_service.encode(query_text)
indices, _ = entity_storage.get_knn(query_embedding, top_k=N)
# 每个语义候选必须通过 link_candidate_score 过滤器
# 只有 has_evidence=True 的候选保留进入 merge 池两条路径的候选 score 取 max 合并,再通过 Personalized PageRank 进行图扩展。
3.3 Stage 3 — Personalized PageRank
这是 GoS 区别于纯向量检索的关键。从 seed skills 出发,通过图结构发现间接相关但语义不直接匹配的技能:
# 转移矩阵构建
for edge in edges:
transition[source, target] += forward_weight
transition[target, source] += forward_weight * reverse_weight[type]
# PPR 迭代 (damping=0.2)
for iter in range(max_iter):
next = 0.2 * personalization + 0.8 * transition.T @ scores
if convergence: breakdamping=0.2 意味着每次迭代 20% 的分数回退到种子节点,80% 沿边传播。这个参数控制的是"发现新技能"和"锚定原始意图"之间的权衡。例如,query "mesh analysis" 可能通过 PPR 发现 obj-exporter(workflow 关系),即使两者没有共享任何关键词。
3.4 Stage 4 — 多因子 Rerank + Context 渲染
PPR 输出的图分数不是最终结果,还需要经过一个精细的 多因子调整:
rerank_score = graph_score (PPR 基础分)
+ name_bonus × 1.25 # 技能名精确匹配
+ domain_tags × 1.15 # 领域对齐
+ tooling × 0.95 # 工具链匹配
+ capability/description × 0.90
+ example_tasks × 0.80
+ I/O types × 0.75
+ script_entrypoints × 0.60
+ artifact_overlap × 0.90 # 文件名匹配
+ semantic_rank × 0.2/rank
+ node_name_in_query × 1.20 # 技能名出现在 query 中最终输出经过 budget 控制:单 skill 最多 2400 chars,总 context 不超过 12000 chars,完美匹配主流模型的上下文预算。
与 GraSP 的互补关系
GoS 和 GraSP 并非竞争关系,而是上下游关系:
- GoS 实现了 GraSP Stage 1(Memory-Conditioned Retrieval 的检索部分)
- GraSP 的 Stage 2-4(DAG 编译 → 验证执行 → 局部修复)是 GoS 不涉及的领域
- GraSP 有 5 种边类型(state/data/order/precondition/effect),比 GoS 的 4 种更精细,但复杂度更高
- GraSP 的情节记忆(episodic memory guidance)是 GoS 完全缺失的——GoS 的检索不考虑历史执行成败
最佳实践路径:用 GoS 做 skill 检索层(Stage 1),在其 SkillRetrievalResult 输出上叠加 GraSP 的 DAG 编译 + verified execution + 5 种修复算子。
MCP 集成 — 对 Hermes 的直接价值
GoS 提供了 7 个 MCP tool,可直接注册到 Hermes(或 Claude Code):
| Tool | 用途 |
|---|---|
search_skills | 快速排名概览 |
retrieve_skill_bundle | 主力工具 — 完整 skill 内容注入 agent context |
hydrate_skills | 按名称精确加载已知 skill |
get_status | 图规模/配置查询 |
list_skills | 浏览全部 skill |
get_skill_detail | 单 skill 完整元数据 + 邻居 |
get_skill_neighbors | skill 的入/出边关系 |
对 Hermes 的直接价值:
- 替换
skill_view(name)为语义化检索,不再需要精确知道技能名称 - 12000 chars context budget 完美匹配模型上下文限制
- 实测 56× token 压缩(ALFWorld,1.5M → 27K tokens)
实验数据
GoS 在 SkillsBench(87 个 dockerized coding task)和 ALFWorld(134 个 household game)上评估了三类模型:
- Claude Sonnet 4.5: SB reward 31.0(vs Vanilla 25.0),token 压缩 56×
- MiniMax M2.7: SB reward 18.7(vs Vanilla 17.2),edge 最明显
- GPT-5.2 Codex: SB reward 34.4(vs Vanilla 27.4),绝对分数最高
关键洞察:GoS 在更大 skill 库(2000 skills)上优势更明显——因为噪音过滤的价值随规模线性增长。
局限与改进空间
- 无执行验证 — 返回 skill 后不检查执行是否成功(GraSP 的核心创新)
- 离线图不可变 — 新增 skill 需 re-index,不支持增量 DAG 编译
- PPR damping 硬编码 — 0.2 对所有查询统一,无自适应机制
- 无情节记忆 — 不考虑历史执行成败(GraSP 的 episodic memory 优势)
- 代码生成依赖 LLM — 边链接依赖 LLM 调用,离线 index 大库时成本高
结论
GoS 是当前最佳的 GraSP Stage 1 开源参考实现。它证明了图结构在技能检索中的实际价值——不是用更复杂的算法,而是用正确的结构来引导检索。如果需要完整的 GraSP 四阶段,从 GoS 起步叠加 DAG 编译和执行验证是最务实的路径。
相关链接:GitHub | arXiv:2604.05333 | HuggingFace Dataset